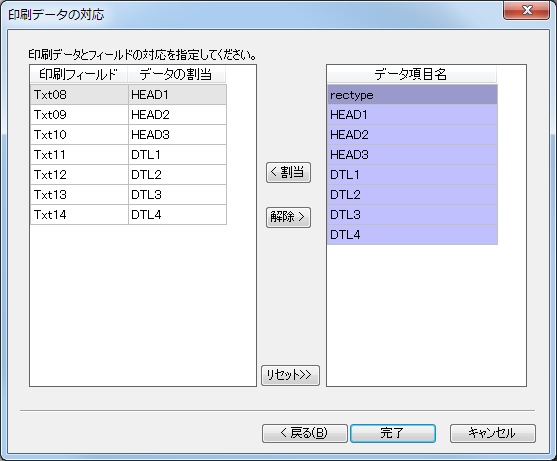
(1) データの書式
印刷データウィザードの「データの書式」で「固定長テキスト」を選択します。
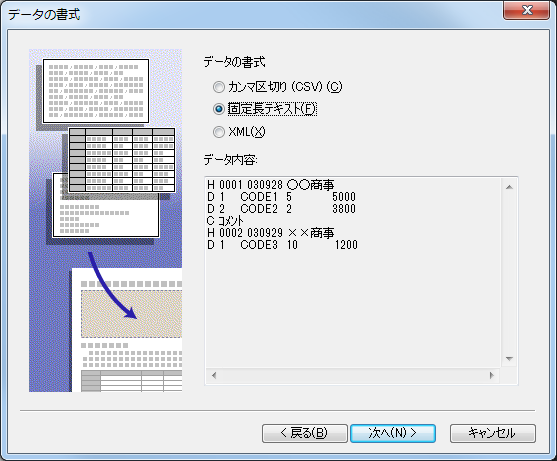
(2) レコード区分
ここでは、複数のレコード様式を持つ固定長テキストの各レコード様式を区別するレコード区分と、項目名の一部となるプレフィックス(接頭語)を指定します。
複数のレコード様式を持たない固定長テキストの場合には「使用しない」を指定します。

「レコード区分」には各行の書式を識別するための記号を入力します。PrintStreamは、固定長テキストの先頭にある文字と指定したレコード区分を比較して行の書式を識別します。
各レコード区分の文字列の長さは原則として一致させる必要があります。文字列の長さ違う場合は、最も長いレコード区分の文字数をレコード区分カラムとして採用します。
「項目名のプレフィックス」には各書式に対応した項目名の接頭語を指定します。
「このレコードは無効とする」をチェックすると、このレコード区分を持つレコードは読み飛ばされ印刷されなくなります。印刷には無関係な行が含まれる場合に指定してください。
固定長テキストで複数のレコード区分を使用する場合は、「印刷データのグループ化と集計」機能は使用できなくなります。
レコード区分を指定した場合の処理イメージを例で説明します。
固定長テキストの構造
|
|
項目名 |
開始位置 |
長さ |
|
|---|---|---|---|---|
|
レコード区分 |
rectype |
0 |
1 |
|
|
H |
伝票番号 |
HEAD1 |
2 |
4 |
|
発行日 |
HEAD2 |
7 |
6 |
|
|
顧客名 |
HEAD3 |
14 |
20 |
|
|
D |
明細番号 |
DTL1 |
2 |
2 |
|
商品コード |
DTL2 |
5 |
7 |
|
|
数量 |
DTL3 |
13 |
4 |
|
|
単価 |
DTL4 |
17 |
6 |
|
|
C |
コメント |
COMMENT1 |
2 |
50 |
上図の構造にしたがった固定長テキストデータの例

このような固定長テキストデータを印刷する場合、次のようにレコード区分を設定します。
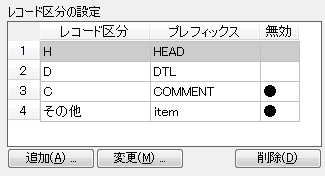
この設定を行うと固定長テキストファイルの読み込みは、次のようなイメージで行われます。レコード区分がCの行とH,D以外の行は読み飛ばされます。
|
rectype |
HEAD1 |
HEAD2 |
HEAD3 |
DTL1 |
DTL2 |
DTL3 |
DTL4 |
|
H |
0001 |
030928 |
○○商事 |
|
|
|
|
|
D |
|
|
|
1 |
CODE1 |
5 |
5000 |
|
D |
|
|
|
2 |
CODE2 |
2 |
3800 |
|
H |
0002 |
030929 |
××商事 |
|
|
|
|
|
D |
|
|
|
1 |
CODE3 |
10 |
1200 |
レコード区分がHの行を読み込んだ場合は、レコード区分がDの項目は空白になります。
逆に、レコード区分がDの行を読み込んだ場合は、レコード区分がHの項目は空白になります。
ただし、レコード区分(rectype)は常に値が入ります。
印刷時は、レコード区分の対象となるレコードのみが印刷されます。
例えば、レコード区分がHの行を読み込んだときは、HEAD1、HEAD2、HEAD3があるレコードのみが出力され、それらを含まないレコードは印刷されません。
フォームの定義

印刷結果

(3) 固定長テキストの項目
ここでは、固定長テキストの各項目の位置を指定します。複数のレコード区分を指定した場合は、「レコード区分」を変更して、それぞれのレコード区分に対して設定します。

「開始位置を自動で計算する」を使用すると、各項目の長さに合わせて位置を自動的に計算します。
(4) 印刷データの対応
既にフィールドか定義されている場合、印刷データとフィールドの対応を指定します。