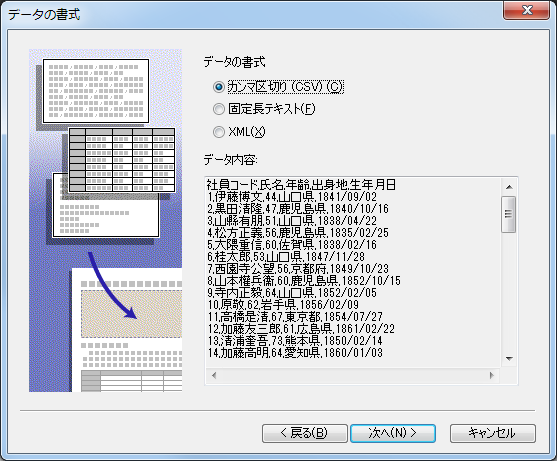
(1) データの書式
印刷データウィザードの「データの書式」で「カンマ区切り (CSV)」を選択します。
(2) レコード区分
ここでは、複数のレコード様式を持つCSVの各レコード様式を区別するレコード区分と、項目名の一部となるプレフィックス(接頭語)を指定します。
複数のレコード様式を持たないCSVの場合には「その他」だけを指定します。
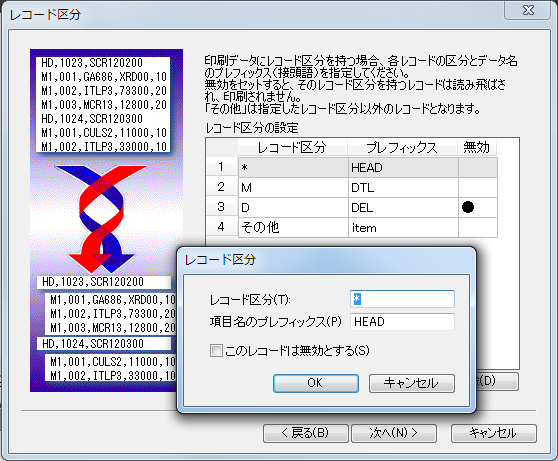
「レコード区分」には各行の書式を識別するための記号を入力します。PrintStreamは、CSVの先頭カラムと指定した記号を比較して行の書式を識別します。
「項目名のプレフィックス」には各書式に対応した項目名の接頭語を指定します。
「このレコードは無効とする」をチェックすると、このレコード区分を持つレコードは読み飛ばされ印刷されなくなります。印刷には無関係な行が含まれる場合に指定してください。
レコード区分を指定した場合、各書式のデータは印刷実行時に1行に連結されます。以下に連結の様子を例で説明します。
CSVデータの構造
|
レコード区分 |
伝票番号 |
発行日 |
顧客名 |
|
|
レコード区分 |
明細番号 |
商品コード |
数量 |
単価 |
|
レコード区分 |
明細番号 |
商品コード |
数量 |
単価 |
|
レコード区分 |
コメント |
|
||
|
レコード区分 |
伝票番号 |
発行日 |
顧客名 |
|
|
レコード区分 |
明細番号 |
商品コード |
数量 |
単価 |
|
: |
||||
上図の構造にしたがったCSVデータの例
|
H |
0001 |
030928 |
○○商事 |
|
|
D |
1 |
CODE1 |
5 |
5000 |
|
D |
2 |
CODE2 |
2 |
3800 |
|
C |
コメント |
|
||
|
H |
0002 |
030929 |
××商事 |
|
|
D |
1 |
CODE3 |
10 |
1200 |
このようなCSVデータを印刷する場合、次のようにレコード区分を設定します。
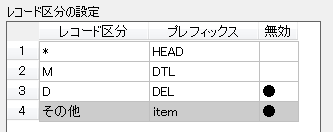
この設定を行うとCSVの読み込みで、次のように連結して処理されます。レコード区分がCの行とH,D以外の行は読み飛ばされます。
|
HEAD1 |
HEAD2 |
HEAD3 |
HEAD4 |
DTL1 |
DTL2 |
DTL3 |
DTL4 |
DTL5 |
|
H |
0001 |
030928 |
○○商事 |
D |
1 |
CODE1 |
5 |
5000 |
|
H |
0001 |
030928 |
○○商事 |
D |
2 |
CODE2 |
2 |
3800 |
|
H |
0002 |
030929 |
××商事 |
D |
1 |
CODE3 |
10 |
1200 |
|
: |
||||||||
レコード区分は、ヘッダ・明細形式のデータのみを扱うことができます。レコード区分ごとに明細行の書式が異なるようなCSVデータや、ヘッダ行と明細行の対応関係が不完全なデータを扱うことはできません。
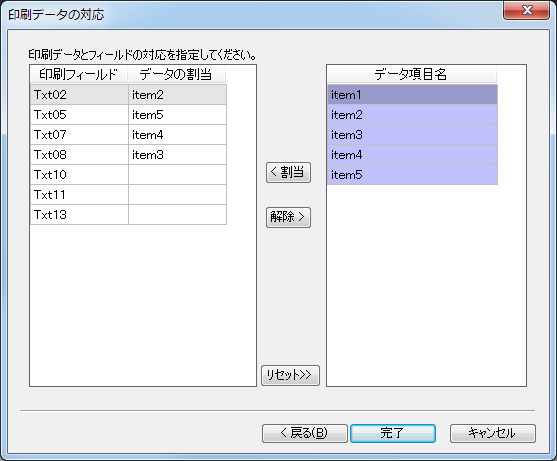
(3) 印刷データの対応
既にフィールドか定義されている場合、印刷データとフィールドの対応を指定します。